48:23~1:57:32까지 수업 내용 필기
1. 슬라이싱
주어진 내용 중 필요한 것만 잘라서 사용하는 것
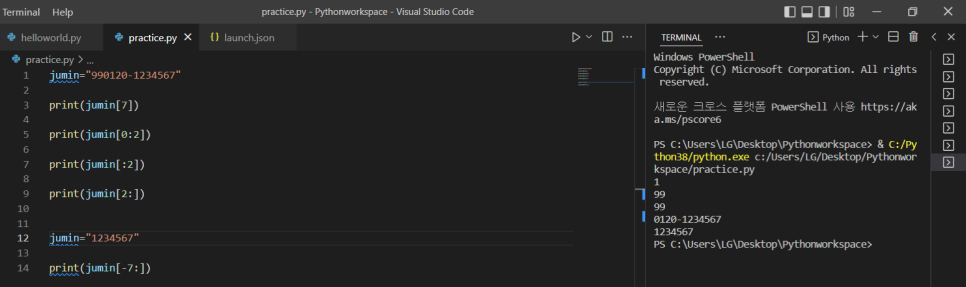
* 순서는 1부터가 아니라 0부터 센다. ex) 12345 -> 1은 0번째, 2는 1번째 ...
1) print(jumin[7]) -> jumin 함수에서 7번째에 있는 값
2) print(jumin[0:2]) -> jumin 함수에서 0번째부터 2번째 직전까지 있는 값 = 0번째, 1번째 값
3) print(jumin[:2]) -> jumin 함수에서 처음부터 2번째 직전까지 있는 값 = 0번째, 1번째 값
4) print(jumin[2:]) -> jumin 함수에서 2번째부터 끝까지 있는 값 = 2번째부터~13번째까지 값
*역으로 순서 셀 때는 -1, -2 ...
ex) 1234567 -> -7,-6,-5,-4,-3,-2,-1 (순서)
=> print(jumin[-7:0]) -> -7번부터 끝까지 있는 값 (1234567로 출력)
2. 문자열 처리 함수
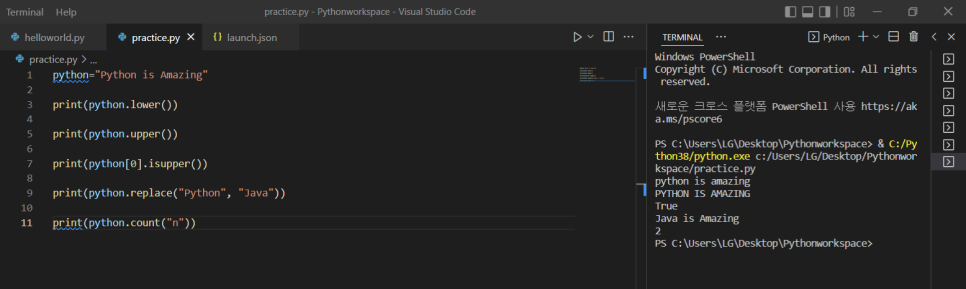
1) print(python.lower()) -> python 함수의 문자를 모두 소문자 처리
2) print(python.upper()) -> python 함수의 문자를 모두 대문자 처리
3) print(python[0].isupper()) -> python 함수의 0번째 문자가 대문자인지에 대해 T/F 로 응답
4) print(len(python)) -> 띄어쓰기 포함한 python 전체 문자의 길이
5) print(python.replace("Python", "Java")) -> python 함수의 Python 이라는 단어를 Java로 대체
6) print(python.count("n")) -> python 함수에서 n이 총 몇 번 등장하는지
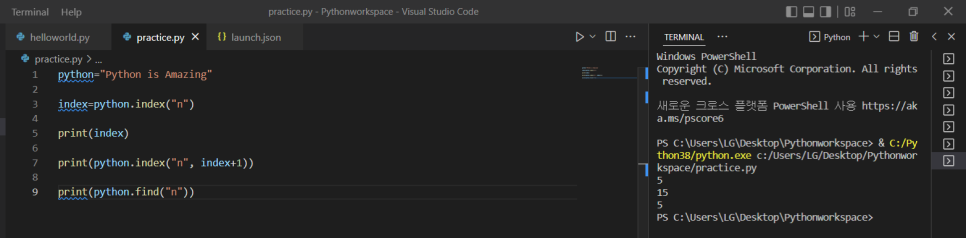
*index와 find (위치)
1) index=python.index("n") -> python 함수에서의 첫번째 n의 위치
2) index=python.index("n", index+1) -> 두번째 n의 위치(첫번째로 찾은 n위치 이후에 나오는 n의 위치)
3) print(python.find("n") -> 1번과 동일하게 n의 위치 알려줌
+) 둘의 차이점 - 없는 문자의 위치 요청할 때
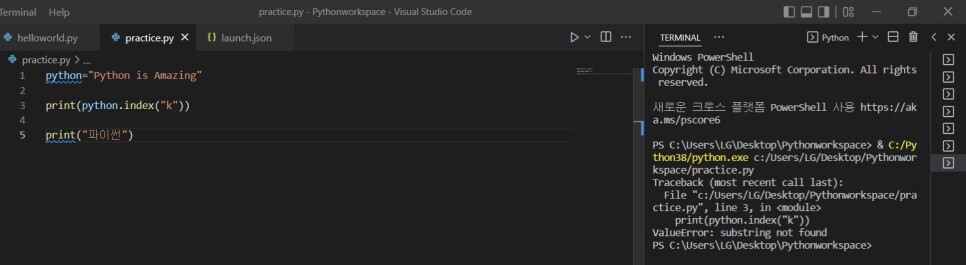
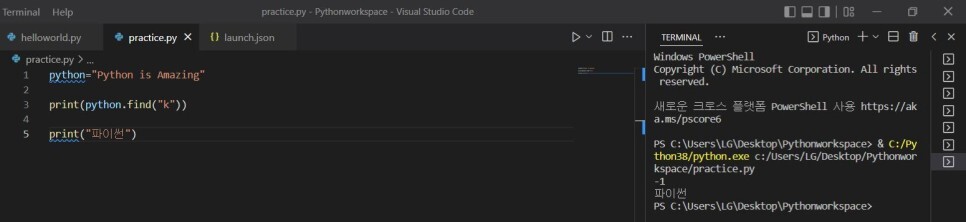
1) print(python.index("k"))
-> 문장에 k가 없으므로 에러가 뜨며 프로그램이 종료되어 이 문장 이후 작성된 코드들 출력 X
2) print(python.find("k"))
-> 문장에 k가 없으므로 -1을 출력하고 프로그램 종료 없이 이 문장 이후 작성된 코드들 정상 출력
3. 문자열 포맷
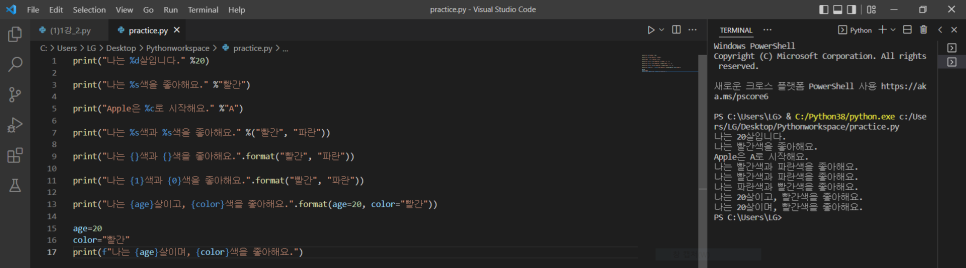
1) %d : 정수
2) %s : 문자열 (string) -> 문자, 정수 모두 가능
3) %c : 하나의 문자 (character)
*두 개 이상 출력하기
1) print("나는 %s 색과 %s 색을 좋아해요." %("빨간", "파란"))
2) print("나는 { }색과 { }색을 좋아해요.".format("빨간", "파란"))
3) print("나는{1}색과 {0}색을 좋아해요.".format("빨간", "파란")) -> 파란, 빨간 순으로 출력
4) print("나는 {age}살이며, [color}색을 좋아해요.".format(age=20, color="빨간")) -> 변수처럼도 사용 가능
5) (v 3.6 이상부터 가능)
age=20
color=빨간
print(f"나는{age}살이며, {color}색을 좋아해요.") -> + 사용 없이 변수처럼 사용 가능.
4. 탈출 문자
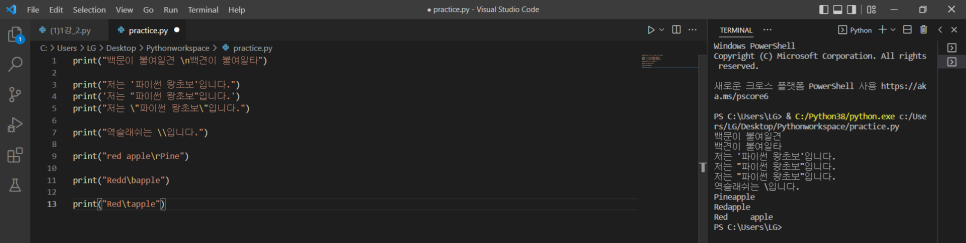
1) \n : 줄바꿈
2) \", \' : 문장 내 따옴표
+) print("~'A'~") 또는 print('~"A"~') 식으로 "와 '를 함께 써서 따옴표 표현도 가능
3) \\ : 문장 내 \ -> 그냥 \ 하나 입력시 이를 탈출문자를 입력하려는 시도로 인식해서 에러남
4) \r: 커서를 맨 앞으로 이동 -> \r 뒤에 나오는 문자 길이만큼 앞에서 자리 차지 (띄어쓰기 포함)
5) \b: 백스페이스, 한글자 삭제
6) \t: 탭
5. 리스트
순서를 가지는 객체의 집합 []
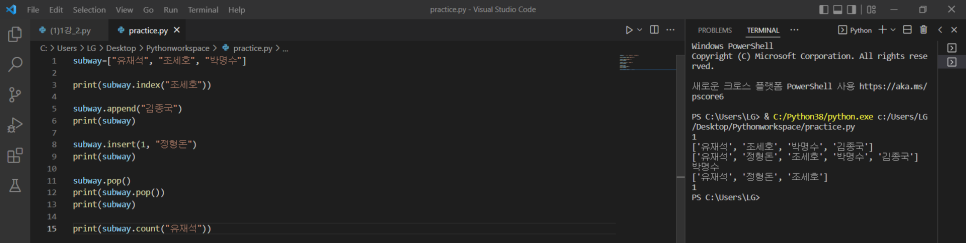
1) 리스트에서 객체의 위치 파악하기
print(subway.index("조세호"))
2) 리스트에 객체 추가하기 - 리스트 맨 뒤에 추가
subway.append("김종국")
3) 리스트에 객체 추가하기 - 리스트 중간에 삽입
subway.insert(1,"정형돈") -> 1이라는 위치에 정형돈 추가
4) 리스트에서 삭제하기 - 리스트 맨 뒤에서부터 삭제
subway.pop()
+) print(subway.pop()) -> subway 리스트에서 삭제되는 개체가 무엇인지 보여줌
5) 같은 이름의 객체가 몇 개 있는지 숫자 세기
print(subway.count("유재석"))
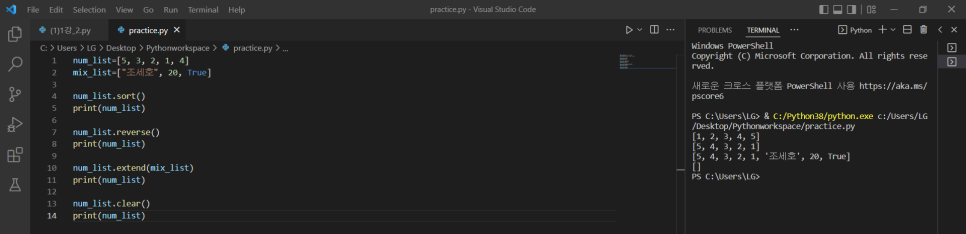
리스트는 자료형에 구애 받지 않고 섞어서(문자, 숫자, boolean) 사용 가능
6) 순서대로 정렬하기
num_list.sort()
7) 거꾸로 정렬하기
num_list.reverse()
8) 리스트 확장하기(리스트끼리 합치기)
num_list.extend(mix_list)
9) 리스트 객체 모두 삭제하기
num_list.clear()
6. 사전
key:value
사전의 key는 단 하나만 존재하고(중복x), key가 갖는 value도 단 하나뿐이다.
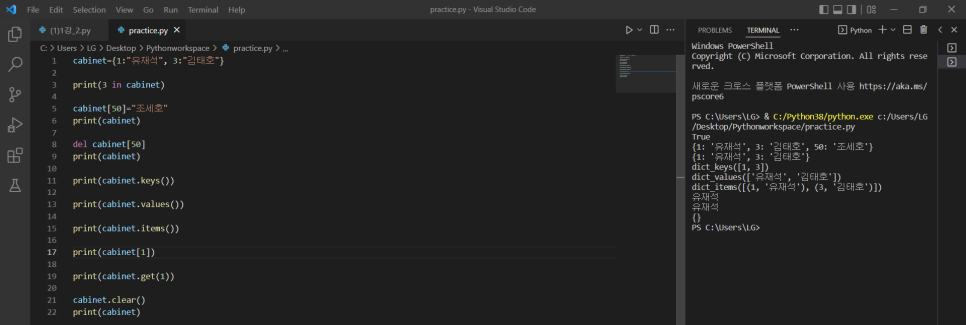
1) 어떤 key 가 사전 내에 있는지 확인하기
print(3 in cabinet) -> cabinet이라는 사전에 3이라는 key가 있으면 T, 없으면 F 출력
2) 사전에 새로운 key 추가하기/기존 key의 값 업데이트하기
cabinet[50]="조세호" -> 50(key):조세호(value) 값을 cabinet이라는 사전에 넣기/기존에 50이라는 key에 다른 value가 있었다면 조세호로 업데이트됨
3) 사전에 key:value 값 지우기
del cabinet["50"]
4) 사전에 있는 key 확인하기
print(cabinet.keys()) -> dict_keys(['key1`, 'key2'...])
5) 사전에 있는 value 확인하기
print(cabinet.values()) -> dict_values(['value1', 'value2' ...])
6) key, value 쌍으로 모두 출력하기
print(cabinet.items()) -> dict_items([('key1', 'value1'), ('key2', 'value2') ...])
7) 어떤 key가 갖고 있는 value 값 확인하는 방법 x2
① print(cabinet[3])
② print(cabinet.get(3))
8) 모든 value 삭제하기
cabinet.clear()
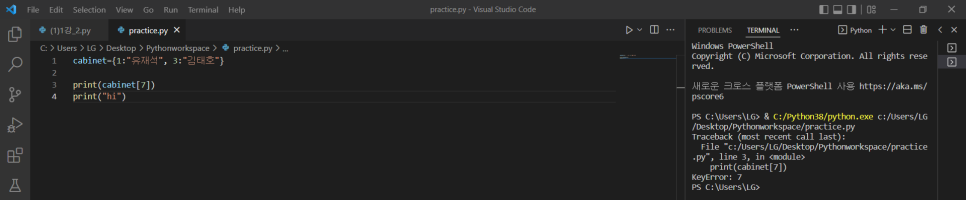

+) 7 방법 두 개의 차이점 - value가 없는 key의 값 요청할 때
1) print(cabinet[7])
-> key 7은 value가 없으므로 에러 발생하고 프로그램 종료되어 그 다음 코드 출력 X
2) print(cabinet.get(7))
-> key 7은 value가 없으므로 None 출력되고 프로그램 종료 없이 그 다음 코드 정상 출력
+) None 대신 다른 기본값이 출력되도록 설정하고 싶다면
: print(cabinet.get(7, "사용가능")) -> 일단 7의 value를 가져오려고 시도해보고 없으면 사용가능 출력
7. 튜플
()
리스트와 달리 내용 변경 불가능 -> 고정된 값에 대해서 사용 -> 할 수 있는 것이 많지 않으나 속도가 빠름
=> 변경되지 않는 목록 활용할 때 튜플 사용

1) print(menu[0]) -> menu라는 튜플에서 0번째 객체 출력
* 활용
(name, age, hobby)=("김종국", 20, "코딩") -> ()가 있으니 튜플 형태. 변수로 써도 되지만 이렇게 한꺼번에 쓸 수도 있음.
8. 집합
set, {}

중복을 허용하지 않고 순서가 없음. -> 중복된 값이 있다면 알아서 제외하고 출력함
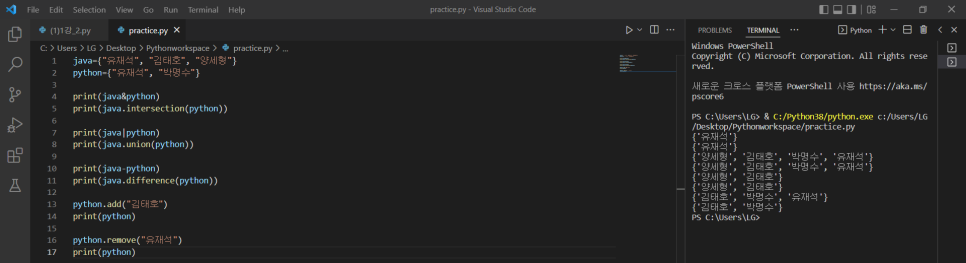
1) 교집합 구하기
print(java&python)
print(java.intersection(python))
2) 합집합 구하기
print(java | python)
print(java.union(python))
3) 차집합 구하기
print(java-python)
print(java.difference(python))
4) 값 추가하기
python.add("김태호")
5) 값 제외하기
python.remove("유재석")
9. 자료 구조의 변경

*자료 구조의 종류 확인하기
: print(menu, type(menu)) -> 메뉴를 출력하고(괄호 형태로 종류 확인가능), <class '종류'> 출력
1) 집합을 리스트화
menu=list(menu)
2) 리스트를 튜플화
menu=tuple(menu)
3) 튜플을 집합화
menu=set(menu)
10. shuffle, sample
shuffle: 랜덤으로 순서 섞기
sample: 랜덤으로 뽑기

from random import *
-> shuffle, sample 함수 쓰려면 꼭 먼저 써야 하는 random module
1) shuffle(lst)
2) print(sample(lst, 1) -> lst에서 1개의 sample 뽑기
'Python' 카테고리의 다른 글
| [Python] 알고리즘, 코딩, 프로그래밍, 파이썬, 세미콜론, 자료형, 연산, 진수, 변수, 할당연산자 (0) | 2022.08.11 |
|---|---|
| [Python] 함수, 전달값과 반환값, 기본값, 키워드값, 가변인자, 지역변수와 전역변수 (0) | 2022.05.10 |
| [Python] if, 반복문, for, while, continue, break, 한 줄 for (0) | 2022.05.08 |
| [Python] 자료형, 변수, 주석, 연산자, 간단한 수식, 숫자처리함수, 랜덤함수, 문자열 (0) | 2022.05.05 |